At EDINA, we strive for resilience in the services we run. We may not be competing with the massive international server-farms that the likes of Google, Facebook, Amazon, eBay, etc run… however we try to have systems that cope when things become unavailable due to network outages, power-cuts, or even hardware failures: the services continue and the user may not even notice!
For read-only services, such as ORI, this is relatively easy to do: the datasets are apparently static (any updates are done in the background, without any interaction from the user) so two completely separate services can be run in two completely separate data centres, and the systems can switch between them without anyone noticing – however Repository Junction Broker presented a whole different challenge.
The basic premise is that there are two instances of the service running – one at data centre A, the other at data centre B – and the user should be able to use either, and not spot any difference.
This first part is easy: the user connects to the public name for the service. The public name is answered by something called a load-balancer which directs the user to whichever service it perceives as being least loaded.
In a read-only system, we can stop here: we can have two entirely disconnected systems, and let them respond as they need to…. and use basic admin commands to update the services as they need.
For RJ Broker, this is not the end of the story: RJB has to take in data from the user, and store that information in a database. Again, a relatively simple solution is available: run the database through the load-balancer, so both services are talking to the same database, and use background admin tools to copy database A to database B in the other data-centre.
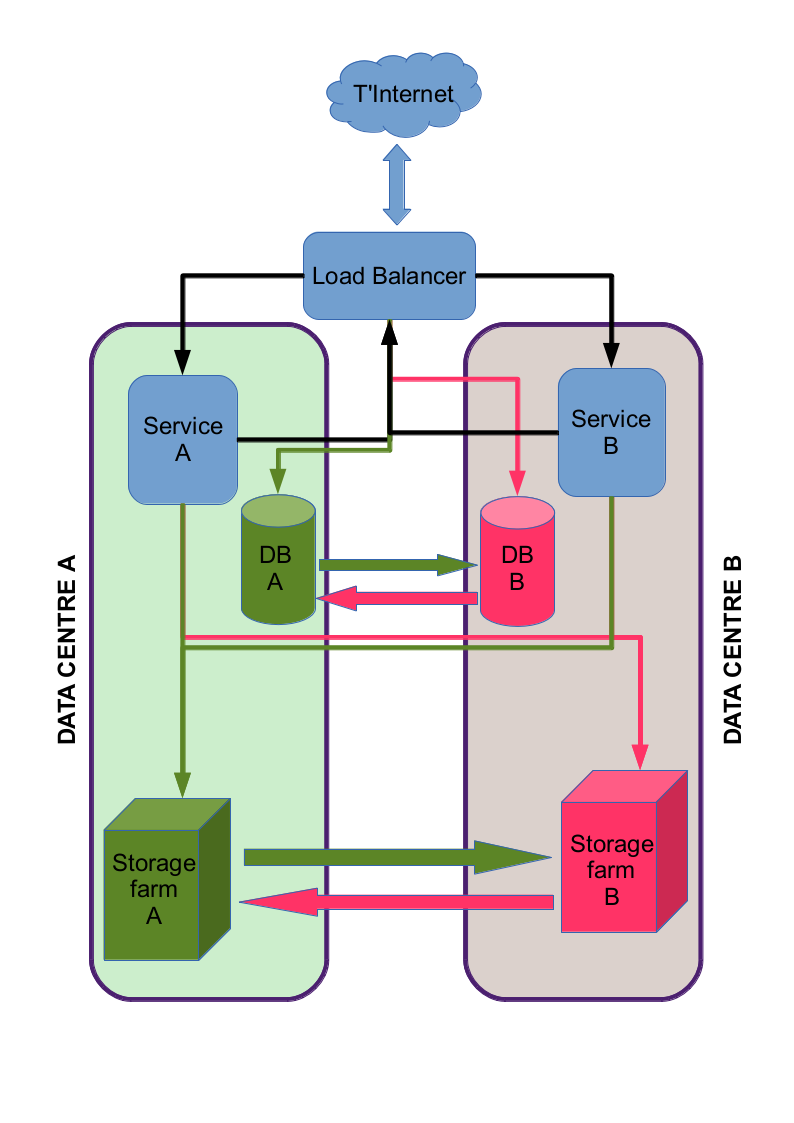 Again, RJB needs more: as well as storing information in the database, the service also writes files do disk. Here at EDINA, we make use of Storage Area Network (SAN) systems – which means we mount a chunk of disk space into the file-system, across the network.
Again, RJB needs more: as well as storing information in the database, the service also writes files do disk. Here at EDINA, we make use of Storage Area Network (SAN) systems – which means we mount a chunk of disk space into the file-system, across the network.
The initial solution was to get both services to mount disk space from SAN A (at data centre A) into /home/user/san_A and then get the application to store the files into this branch of the file-system…. meaning the files are instantly visible to both service.
This, however, is still has the “single point of failure” which is SAN A. What is needed is to replicate the data in SAN A in SAN B, and make SAN B easily available to both installations
The first part of this is simple enough: mount disk space from SAN B (in data centre B) into /home/user/san_B. We then use an intermediate symbolic link (/home/user/filestore) to point to /home/user/san_A and get the application to store data in /home/user/filestore/... Now, if there is an outage at Data Centre A, we simply need to swap the symbolic link /home/user/filestore to /home/user/san_B and the application is none-the wiser.
The only thing that needs to happen is the magic to ensure that all the data written to SAN A is duplicated in SAN B (and database A is duplicated into database B)

Leave a comment